

Is DataOps flattening or is it just starting?
Is DataOps flattening or is it just starting?
The growth and adoption pattern of the modern data stack

The sigmoid curve of data economy
Technological advancements never progress linearly, but rather go through a non-linear transition state that follows the sigmoid curve, a mathematical function with the characteristic "S"-shaped curve. The curve has been observed in the growth and adoption of many technologies in history. For instance, in 1874 Thomas Edison invented the telegraph multiplexer, which quadrupled the data throughput of traditional telegraph lines. This invention disrupted the wire communication industry and opened the floodgate to other innovations that improved the way people communicate. For technologies following this sigmoidal lifecycle, three stages are typically involved:
A stage where the technology originated from its enabling point
An exponential growth and adoption period where the technology dominates the market and is massively favored by its users.
A plateau post the exponential growth stage as the technology matures in development and penetration
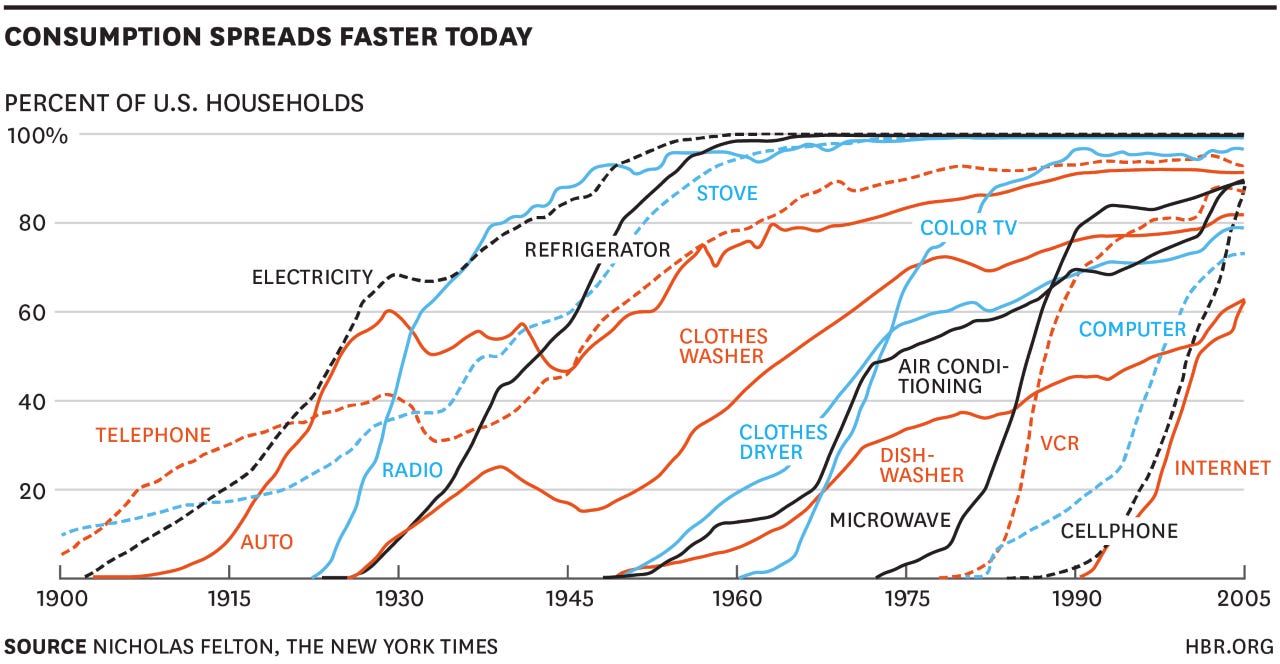
Following the same sigmoidal pattern, the modern data stack (MDS) mostly originated from the release of Amazon Redshift in 2013. Even though a multi-parallel processing database (MPP) existed a few decades before Amazon Redshift, Amazon Redshift was the first cloud-native MPP, more specifically online analytical processing database (OLAP), that unlocked the database’s ability to handle complex joins and analytical queries with 100X processing efficiency and extremely low latency. Most importantly, it only costs a couple of hundred dollars per month! Following the emergence of Redshift, every vertical development of the modern data stack (e.g. fully managed ETL data pipelines, cloud-native data warehouse/lake, querying, processing and transformation blocks, and BI visualization) on the market today emerged and bloomed in the period from 2013 to 2017.

In the past five years, developments in the operationalization of the modern data stack seem to have hit a bit of a plateau. Recent advances in each component of the data stack are mostly incremental, such as improving the reliability of operation in different environments (check out this great read from a16z), streamlining product functions, adding more orchestration options, and enhancing user experiences and customer onboarding processes. As a whole, the entire data stack hasn’t undergone such drastic changes. This plateau is the third phase in the sigmoidal curve that indicates a degree of maturation in the sector, but this stability could also germinate secondary technologies reliant on the modern data stack and kickstart new explosive growths. One such development is in the space of DataOps. While still in its early days, DataOps is poised for explosive growth built on top of the foundations set by the modern data infrastructure.

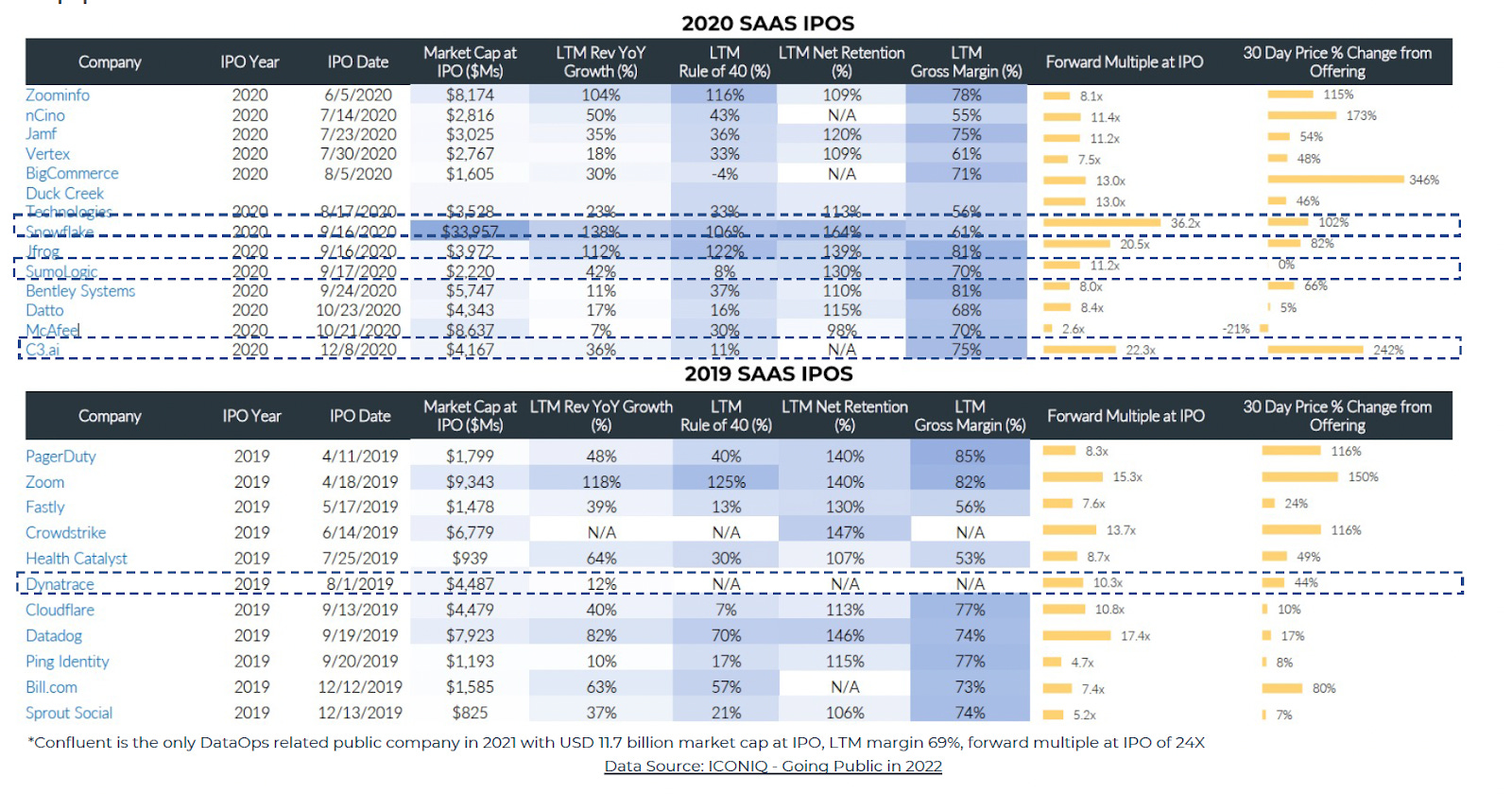
DataOps’s potential for new growth is also evident in its market performance in the past few years, and in the return, it generated for investors. From 2019 to 2021, the trading multiple for publicly traded DataOps companies in the growth stage was around 20.4X, whereas the median multiple for other SaaS companies in a similar stage was around 13X. In addition, DataOps companies had an average market cap of USD 11 billion at IPO with 69% LTM gross margin, higher than the average enterprise software IPO market cap of $3.7B and 67% LTM gross margin in the same period. From the public market perspective, DataOps and the emerging MLOps space are expected to stay strong for at least the next 3-5 years even with the pull-back of the public market right now.
Opportunities in the next DataOps Superorganism
The aggregate growth trajectory is a useful indicator of near to medium-term outlook for companies, but investors should always dig beneath the surface to understand the underlying critical growth drivers and the sustainability of the growth to more accurately foresee opportunities. In the last decade, the maturation of scalable compute infrastructure (e.g. microservice, Kubernetes, serverless, etc.) has granted most tech companies the liberty to focus less effort on infrastructure management and more on software development. This shift subsequently lessened the burden of achieving operational excellence and allowed companies to strive for fine-grained data analytics and to pour more resources into developing data-driven products. As this trend continues, and as corporations begin to realize the growing impact of data on their bottom lines, corporations are starting to place more emphasis on higher-level data-centric applications like AI and ML to drive their business forward. In a symbiotic effect, the desire to advance data applications is also driving increasing investments back into MDS as a whole: companies are investing more earnings EBIT into data and AI developments, from 22% in 2020 to 27% in 2021, according to McKinsey. Industry-wide, companies are re-platforming their data infrastructure from on-premise solutions to the cloud, expanding DataOps use cases and related budgets, and enhancing the unit economics of implementing DataOps. In addition, with increased demand, data warehousing solutions and periphery services (e.g. cataloging, ingestion, transformation, storage, processing, analytics, etc.) in the modern data stack continue to mature, which further accelerates innovations.
While all signs are pointing toward sustainable growth for MDS, as of now, companies still using the traditional data stack are still experiencing some acute pain points while they transition into the modern data stack:
The ever-growing data is sprawled across different sources, coming from OLTP databases, logs, events, and applications. For companies that just started their modern data stack journey, their evolving and fragmented data stack can hardly catch up with the exponential growth in data volume, diversity, and velocity
Most existing data stacks implemented by companies are vertically oriented, assembled using multiple components – ranging from connectors to UI layer to metric and monitoring layer. This patchwork of tools requires the data team to have tons of know-how and overcome multiple deep learning curves to build and maintain their data stack. This situation is further exacerbated by the knowledge loss following employee turnovers
With so much knowledge needed to operate a traditional data stack, the most painful part is building the data engineering team itself. The high demand for engineering talent across multiple industries has outstripped supply for a while now. In fact, in a conversation with a growth stage company’s founding team, they told me that after interviewing 100 data infra engineers, only 1 or 2 candidates were qualified for the position! The situation is even direr in smaller companies, which often lack both a formal data infra team and the resources and budget to hire a world-class team like most growth-stage companies. To compound the problem further, smaller companies stand to benefit the most from modernizing their data infra as they seek a competitive edge and maintain flexibility in changing conditions.
The multiplicity of horizontal developments taking place in MDS recently reminds me of the formation of a “superorganism” in biology. A superorganism is a group of synergistically interacting organisms –such as an insect colony – that functions as a larger organic whole. Similarly in MDS, different components of the stack are growing together to maintain homeostasis, and to ensure that the sector as a whole can thrive and continue to scale. Therefore, if a DataOps superorganism were to emerge, it would require a synergistic interplay between all the tools that have been developed over the past few years. Each component of the current data stack should play nice with each other, and extensive vertical integration will be needed to help remove bottlenecks in operations.
One important insight I gained from my study on this topic is that all growth stage companies’ data stacks look almost the same. For instance, the underlying data stacks of Robinhood, Uber, and Instacart are very similar. This is mostly because the same experienced engineers jumped from company to company to reproduce similar solutions to fulfill fundamentally the same data infrastructure needs. As these cookie-cutter data stack elements continue to be implemented, the opportunity naturally arises to try to commoditize them and create a standardized and integrated platform. And that was precisely what happened:
Productized data stack components will merge and become a unified DataOps service, which is called data infrastructure-as-a-service
Even though players like Databrick and Snowflake are becoming the next data platform themselves, the ‘bricks’ Databrick is offering is still too chunky for SMB or traditional company as they don’t have the infra yet to digest and implement. These are companies that don’t have a full-fledged data team and lack the experience in using these blocks to pull off the full-stack MDS efforts due to complexities in data sources, the steep learning curve in choosing the provider, and building the connectors. I’ve seen an early-stage startup that is unlocking the entire data infrastructure for companies by providing user-defined DAG(directed acyclic graph) to hide complexities for the data infrastructure and package the cloud resources management, Kubernetes to Docker management, into the DAG. This is more of a method for productizing the job of data infrastructure engineers. There are also startups like Iomete that try to standardize the entire offerings by building an all-in-one integration platform and modularizing each offering on top of open source solutions to help the company eliminate maintenance and have seamless integration
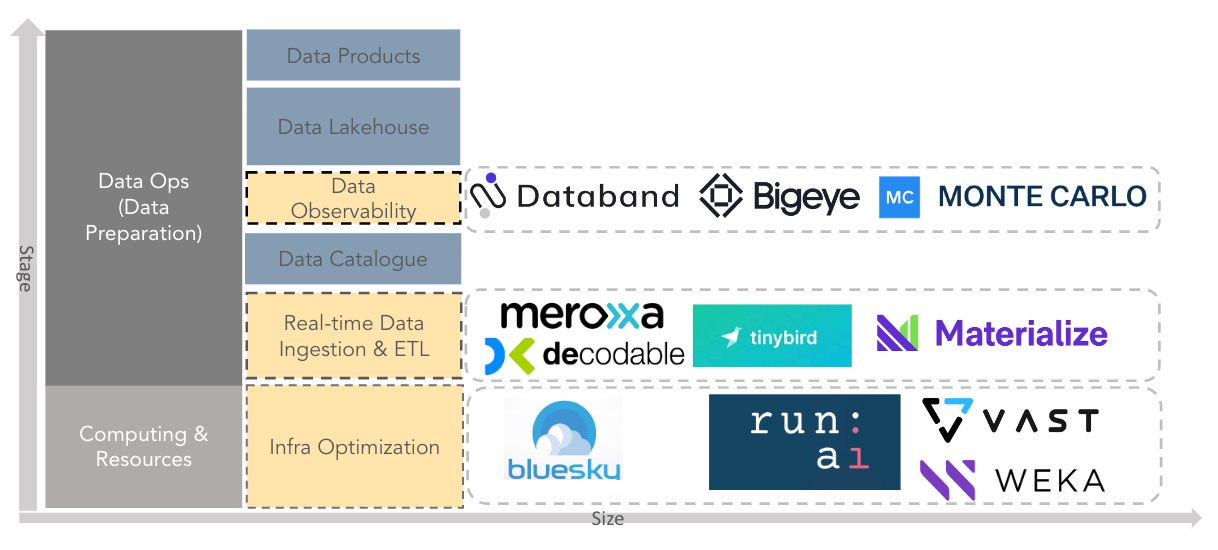
Deepening the vertical development and adding missing mechanisms for the entire ecosystem is another aspect of the starting opportunities for DataOps. Digging into the stack vertically, here are three key areas where most of the opportunities in DataOps will come from for the next 3-5 years:
Infrastructure (Computing & Storage) Optimization
Evolving computes and storage infrastructures are the backbone of the booming DataOps and MLOps industries. The increasing complexity of data and ML models necessitates faster, cheaper, and more efficient cloud storage and computation. MLOps ecosystem has made significant leaps in this alley. From the hardware side, companies like Habana and Hailo are crafting new AI-dedicated chips for data centers, and companies like Run: AI is virtualizing existing clusters of GPUs. In addition, VAST Data and Weka are increasing storage speeds and optimizing data centers to handle the steep requirements of modern AI/ML applications, and Bluesky is a new player in the space that aims to optimize data warehouse costs by managing to compute based on
The next Datadog for DataOps
As data pipelines evolve, they are no longer straightforward one-way flows that pipe data from the source to the sink. Instead, they are becoming complex, interconnected pipelines with multiple intermediate steps. Facing such complexity, a data lake is becoming more like a data swamp, filled with stale, inconsistent, and erroneous data. Plus, small to medium-sized startups and non-tech corporations do not have well-equipped data teams, so problems in data consistency and observability are even more difficult to manage and require even more need for DataOps. Services that bring transparency into companies’ data pipelines and improve data quality are getting noticed, and are starting to emerge in companies’ budget lines. Therefore, full-stack data observability providers like BigEye are poised to take over the full-stack solution for improving data pipeline reliability to increase data quality and health
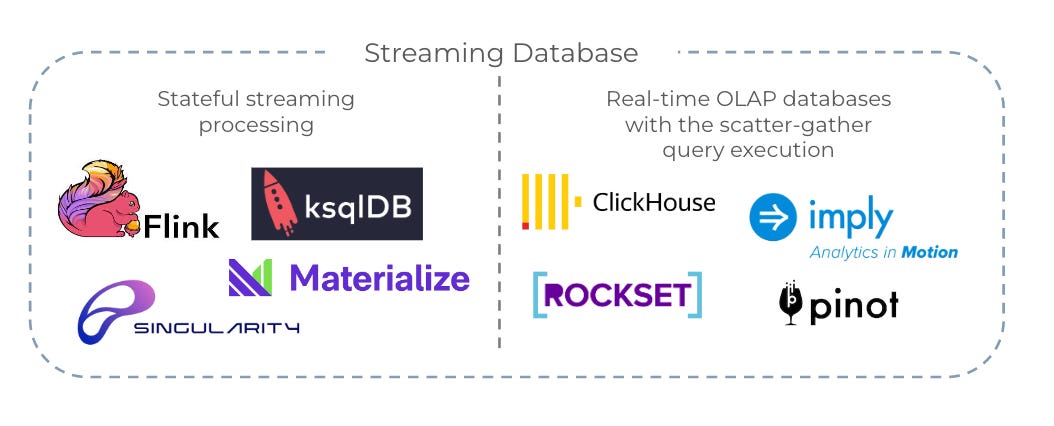

Streaming data processing (Real-time low-latency database & analytics)
DataOps has been picking up speed in the last few years, but data freshness – real-time data streaming with immediate availability for querying with millisecond latency – has become an industrial-wide pain point. Real-time OLAP databases designed to answer complex OLAP queries with millisecond latency at very high throughput (more than 100k QPS) are still in the early stages of development, but accelerated adoption of engines like Flink, ksqlDB, and most recently Materialize that use principles of stateful stream processing, promise to keep those query results incrementally updated as new data comes in. In addition, streaming databases like Apache Druid, Apache Pinot, ClickHouse, and Rockset are working on other solutions to the problem by ingesting incoming data to build structures called “segments,” which are then sent to and indexed on different servers to minimize data input-output time. Real-time continuous intelligence platforms like Infiyon have also demonstrated the shifted landscape from batch-processing to real-time processing
In the next post, I will dig deeper into the emerging players in this space and discuss several growth-stage players and their engineering insights. I’ll also grow upon my analogy of the DataOps superorganism by sharing my take on its upcoming trends, based on all dimensions I mentioned in this post. See you all in a bit!!
Reference Reads:
https://www.getdbt.com/blog/future-of-the-modern-data-stack/
https://medium.com/event-driven-utopia/the-origins-of-olap-databases-and-where-are-they-heading-in-2022-28baa6fef417
https://medium.com/event-driven-utopia/the-state-of-data-infrastructure-landscape-in-2022-and-beyond-c57b9f85505c
https://hhhypergrowth.com/a-kafka-deep-dive/