
Anything and Everything about Generative Models
Primer for the shifting landscape and applications for Large Language Model

The Evolution: on the measure of AI Intelligence

Source: Image generated by Dalle-2 (Prompt: The future of generative ai)
From machine learning to the recent generative foundation model, the story of AI has been about AI’s increasing ability to understand, process, and homogenize multimodal applications. Starting with the introduction of machine learning, the predictive algorithm knows how to automatically learn and infer from historical data and use it to make future predictions. Despite the model knowing how to learn from the dynamics using generic learning algorithms, such as logistic regression, some complex tasks involved in answering logical questions in NLP and image recognition in computer vision still required heavy feature engineering from domain experts.
Until 2010, deep learning, a neural network-based machine learning space fueled by large datasets and computational power, brought the homogenization of AI applications to the next level. Instead of having bespoke feature engineering for each application, one standard architecture can be applied to many applications and allow AI systems to achieve implicit understandings of multiple complex problems without having been explicitly programmed to do so.
Since 2018, AI has undergone seismic changes with the emergence of foundation models – a class of machine learning models (e.g., GPT-3, Dalle-2, CLIP, BERT) enabled by self-supervised transfer learning at scale. Self-supervised learning does not require annotated data for training and therefore removes data labeling overhead. The idea of transfer learning is for the model to take the knowledge learned from one task and apply it to another by pretraining a base model, then later adapting it to downstream tasks via fine-tuning. While self-supervised learning and transfer learning have existed for a while and have made the foundation models possible, it is the improvements in computing hardware, the development in transformer model architecture, and the wide availability of data across industries that make the foundation model so powerful.
In the past few years, the power of the foundation model has stretched our imagination of what is possible: the model can be trained on a surrogate task and later apply the learned knowledge from that task to many other downstream tasks. More importantly, it homogenizes all transformer-based sequence modeling so that any improvement in one model will bring immediate benefits for all other models (you can read more about transformer-based architecture HERE in text, image, speech, tabular data, reinforcement learning, etc.). Fast forward to this year, more open-source large models have emerged and are starting to compete with models from established academic labs at a breakneck speed. Deploying and distributing a single model to the AI community has also accelerated.

Source: Stateof.ai 2022
Foundation models have taken shape most strongly in the NLP space and have the most applications in language generation tasks so I will focus the story there for the moment. That’s not to say that foundation models only exist in NLP. They go beyond NLP and should be perceived as a general paradigm of AI and deep learning. GPT3, with 116B, the size of parameters of its predecessors, proved beyond a doubt to be a heavy weight of language-generating applications for songs, poetry, code, and more. On the one hand, the model is good for a broad array of language tasks. On the other hand, it has major shortcomings in engineering that prompt a lot of biased behaviors and misinformation.
Before OpenAI released a new version of GTP3 earlier this year with the name “Instruct GPT3”, another model used Reinforcement Learning from Human Feedback (RLHF) to follow human instructions and achieved a much higher AI alignment score. The evolved Instruct GPT3 is essentially the same engine (Davinci or Ada), except it was fine-tuned, and the model added a new reward-based reinforcement learning to better align with human preferences. Notably, Instruct GPT3 could open the floodgate for developing smaller, highly specialized language models that could be applied in more niche verticals with lower inference costs. Moreover, developers can train such a model with a single GPU, as fine-tuning only needs <2% of GPT-3’s pre-trained compute and 20,000 hours of human feedback. Most importantly, participants in the research paper preferred the sentence completion quality of Instruct GPT3 over GPT3 Davinci, indicating the possibility of opening up certain verticals to competition with OpenAI (i.e., Instruct GPT3 used in writing or translating fiction far exceeds the classic GPT3 Davinci model in terms of sentence completion).
Looking back on the past decade of developments in language models, the underlying model and implementation have made significant advancements in both homogenization in technology and specializations in applications. Going forward, the entire landscape of AI-driven applications will be at a tipping point very soon, with new excitements and developments emerging from specific areas, which we’ll dive into next.
The shifting landscape of applications for the evolving intelligence
Image-based models, such as Dalle-2 and Dalle-E, have recently ignited great artistic and creative movements in online communities due to the novelty of generative models. As AI is generally better at creative tasks than logical tasks, I will focus my discussion on applications more closely related to human logic, such as conversation, search, code communication, and knowledge base.
Landscape1: The commoditization of Large Language Model (LLM) - the backbone of conversational AI
The entire ecosystem of large language models (the segment at the top of the graphic) has been blooming in the past two years, with the ever-increasing number of models becoming available in both commercial and open-source communities (a more detailed guide HERE). While the cost of developing in-house LLMs stays prohibitive, access to existing LLMs has been democratized via standardized APIs and playgrounds. Plus, most training data for existing LLMs are publicly available. With high model development velocity and increasing accessibility to new models, one can reasonably assume that the mixing of LLMs for different use cases and functionalities will inevitably happen in the near future. Consequently, companies in this space won’t gain much first-mover advantage as others can quickly follow, clone, implement and improve – effectively turning LLMs into commodities.
To stave off the commoditization of LLMs, companies need to specialize in the application of LLMs and gain proprietary ownership of their codebases and relevant unstructured and unlabeled data. For instance, a medical chatbot company will need to build its chatbot using proprietary messaging and user behavioral data and augment the LLM with a unique source of EHR data. If that happens, we may see more verticalized and data-centric use cases with data flywheels built around the models, where new user-generated data will form a data feedback loop that will feed back to the model as new training data.

Landscape 2: The deepening and expansion of LLM use cases in vertical enterprise applications
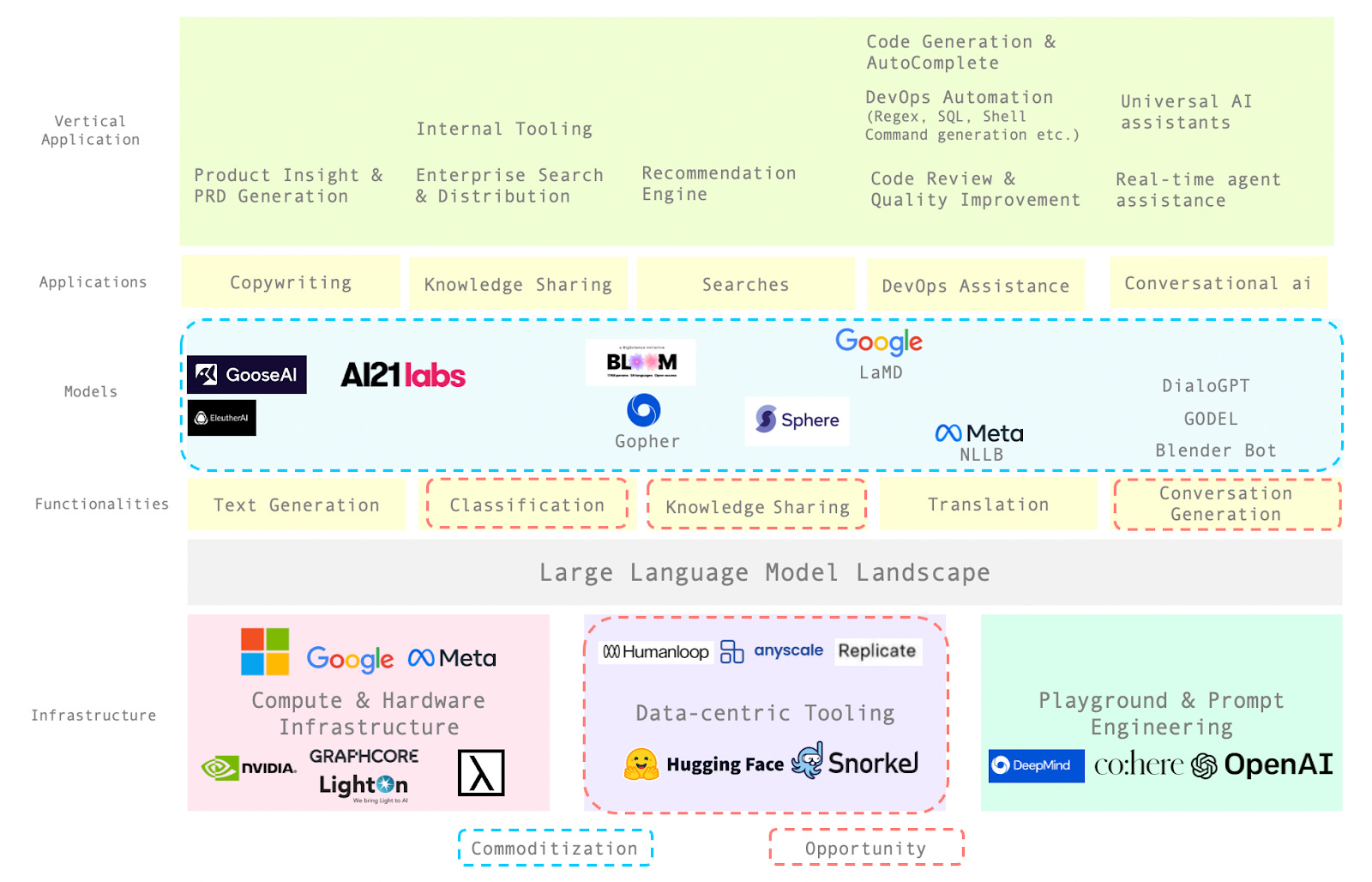
So far, text generation has gained impressive traction in solving straightforward but useful problems related to natural language understanding in commercial applications. But LLMs can also unlock more complex enterprise use cases in document classification, knowledge sharing, and conversational intelligence (conversation generation).
a. Intent and contextualized understanding of conversational AI for Contact Center
Applications of conversational AI have received overdue attention in the past two years (the entire conversational AI ecosystem guide can be found HERE). Still, the hype has not lived up to the expectations of the great business values that could be delivered, so the industry is entering a phase of “disillusionment.”
Companies that have pocketed most of the funding in the space are building conversational solutions around sales and customer experiences (e.g., real-time sales assistance, call automation for CX call centers, etc.). Even today, most so-called “conversational AI” is built on decision trees and keyword routing, essentially rule-based approaches. Take the most prevalent use case of Contact Center AI (CCAI) in call centers; for instance, conversational AI functions as the gateway for triaging incoming calls, but it doesn’t have any capability to understand customers’ intent, let alone manage the customer’s expectations. The fact that conventional CCAIs still need extensive human intervention in the loop explains why most solutions are having trouble deploying to call centers at scale.

Source: Gartner
However, the recent maturation of LLM and foundation models will enable exciting developments in CCAI technologies. For instance, the new models will more rapidly and accurately annotate conversations from call center customers, which will accelerate the development of smaller and smarter language models for use cases that have low feasibility but high business values, such as post-call wrap-up text analytics that will be used in quality assurance, quality management, and agent performance measurement.

Despite LLMs’ recent advances in churning out specialized NLP applications and ample opportunities to evolve quickly by leveraging the proprietary data flywheel, truly successful penetration of conversational AI into CCAI will depend on the chatbot’s ability to understand the customer's intent during conversations. Achieving contextualized understanding will fuel the development of more humanistic conversational assistants and enable more personalized service and dialogues. However, thus far, this goal has not been achieved.
One major reason is the limited amount of diverse training data required to train rare intents that are encountered only sporadically but are nevertheless important to the overall conversational quality. Even though as few as 20 user utterances per intent are enough to train an NLU model, a scarcity of data in the long-tail distribution of intents makes a robust model difficult to achieve. Consequently, those poorly trained sub-intents or nested intents lead to bad conversations and frustrating customer experiences. Discovering and accounting for those niche utterance clusters remains a significant challenge, so building deeper taxonomy and intent clusters will ultimately be vital to CCAI’s success.
b. Structuring, sharing, distribution, and searching for enterprise knowledge
For the past two decades, Google Search has been the dominant search engine for the public internet. Yet there exists no comparable search engine for querying proprietary enterprise information. The reason is two-fold. One, enterprise-specific (working-level) data are siloed within companies due to the sensitive nature of the data. Each data silo contains a wide variety of data types and structures, which are difficult to index using a single tool. Two, the concept of a centralized enterprise-level search engine doesn’t exist yet.
However, lacking such an enterprise search engine doesn't mean it’s unnecessary. As more enterprises embrace a data-centric mindset, various business and internal organizational activities are starting to generate mountains of qualitative and unstructured text data, ranging from Zendesk customer service tickets to brainstorming sessions via Zoom meetings to daily communication in Slack, just to name a few. That collective knowledge and data created across a company are mostly sitting idle with different vendors or in some obscure internal data lake, with little to no value generated. At best, that knowledge may only be useful to the employees who produced the data and worked closely in the business unit. But this poses a high risk as companies can lose valuable institutional knowledge when people leave an organization.
For enterprises, making sense of unstructured and often qualitative text data remains one of the most exciting areas. So to better leverage that treasure trove of data, enterprise search startups like Zir, Glean, Hebbia, & Algolia (through GPT-3) have built search engines on top of LLM to start allowing company employees to find whatever information they need by searching text data and SaaS applications. Generative LLMs can transform this filtered but still jumbled information to synthesize condensed and valuable knowledge assets to distribute to downstream business applications. Some examples include automatic company wiki generation after each virtual and collaborative discussion, technical blog generation or customer experience reports based on Zendesk customer tickets, and summarization of team discussions on Slack.
In addition, LLM will transform the practice of copywriting and drafting product requirements documents by leveraging GPT-3’s ability to generate long-form technical documents from short text inputs. Eventually, a holistic AI-driven approach will emerge that could change the entire landscape of how enterprise-level knowledge gets collected, explored, structured, and distributed.
c. The emergence of cross-functional AI assistants for improving productivity
The concept of a universal personal AI assistant that could comprehend nuanced human instructions and perform tasks in response may sound like science fiction. Still, companies like Adept.ai have made a bold attempt and released their first large model, ActionTransformer (ACT-1), that can take high-level requests from humans and execute them. The guided AI can even perform some cross-functional tasks in real-time, such as observing actions taken in the web browser (e.g., clicking, typing, scrolling) and autocompleting downstream tasks that involve multiple programs, such as cleaning an Excel spreadsheet and entering the processed data into Salesforce.
At the enterprise level, a big upcoming theme for universal AI assistant is bringing more productivity into the enterprise’s workflow – an aspiration that has been tackled before by robotic process automation (RPA) but did not yield fruitful results as RPA cannot understand most human intents and perform tasks in contextualized settings. With the new wave of cross-functional AI assistants that aim to transform operational workflows into conversations, those assistants will be able to contextualize workflows, empower self-service solutions, and even make human-like decisions on behalf of employees in their daily work. Companies like Kubiya.ai are developing conversational AI for DevOps, which provides end-users with secure, on-demand access to cloud resources, operational workflows, and organizational knowledge.
Data-centric tooling for igniting LLM-driven application development
Even with the recent advances in LLMs, we still haven’t seen mass adoption of those language models in our everyday lives, at least not in the same way that image generation models (e.g., DALL-E, Stable Diffusion) have. One main reason may be the lack of mature development infrastructure. Even though some no-code playgrounds allow users to test out LLMs, we haven’t seen many third-party tools or marketplaces that focus on prompt engineering – the process of converting tasks to a prompt-based dataset (i.e., tasks as questions instead of instructions that are implicitly given) to improve model performance.,.
Companies that want to differentiate themselves in this space should adopt a more data-centric and less model-centric mindset. This means focusing on developing data-centric toolings that will support end-users with the means to cluster unstructured text data, generate embeddings for semantic search, and a platform with unified no-code/low-code UI.
The past few years have seen an explosion of exciting new advancements in generative models, which resulted in a lot of buzz in the developer, founder, and investor communities. And there’s still much more to come! In this post, I covered some promising developments, including infrastructures that power data-centric model developments, more specialized and personalized models that can understand human intent and learn from human feedback, and multimodal learning models that create knowledge graphs for AI. The brightest minds will lead the way in this quest, and the companies they build will define this second wave of advanced AI. If you’re a founder who will build the next big thing in this area, my team and I would love to talk with you!